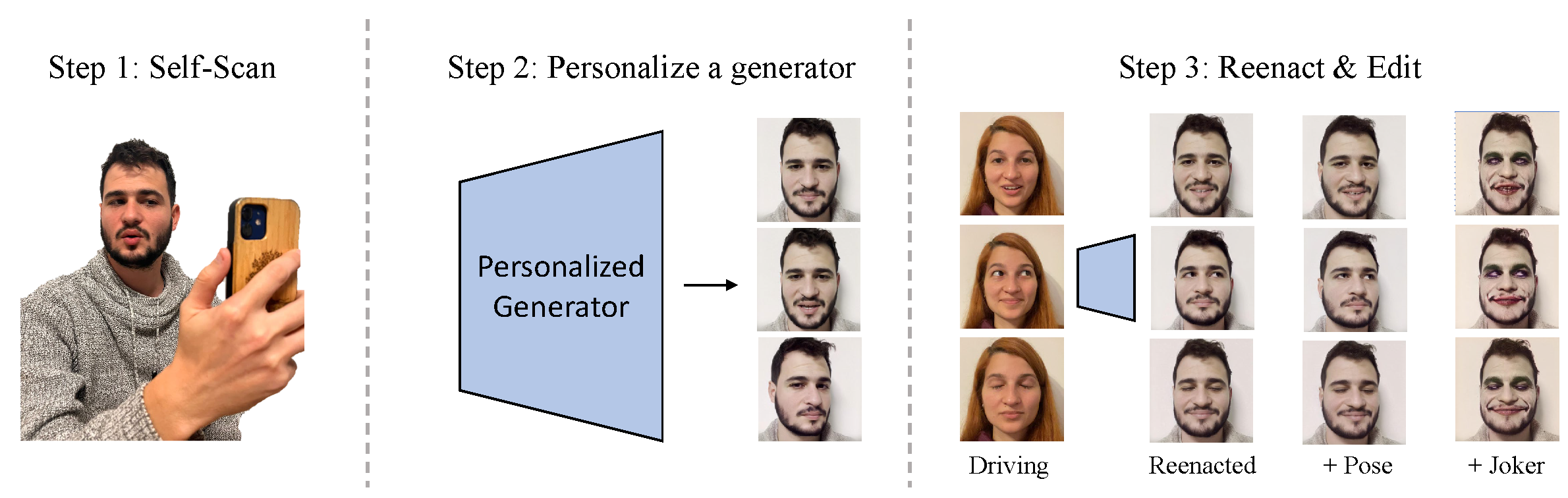
In recent years, the role of image generative models in facial reenactment has been steadily increasing. Such models are usually subject-agnostic and trained on domain-wide datasets. The appearance of the reenacted individual is learned from a single image, and hence, the entire breadth of the individual's appearance is not entirely captured, leading these methods to resort to unfaithful hallucination. Thanks to recent advancements, it is now possible to train a personalized generative model tailored specifically to a given individual. In this paper, we propose a novel method for facial reenactment using a personalized generator. We train the generator using frames from a short, yet varied, self-scan video captured using a simple commodity camera. Images synthesized by the personalized generator are guaranteed to preserve identity. The premise of our work is that the task of reenactment is thus reduced to accurately mimicking head poses and expressions. To this end, we locate the desired frames in the latent space of the personalized generator using carefully designed latent optimization. Through extensive evaluation, we demonstrate state-of-the-art performance for facial reenactment. Furthermore, we show that since our reenactment takes place in a semantic latent space, it can be semantically edited and stylized in post-processing.
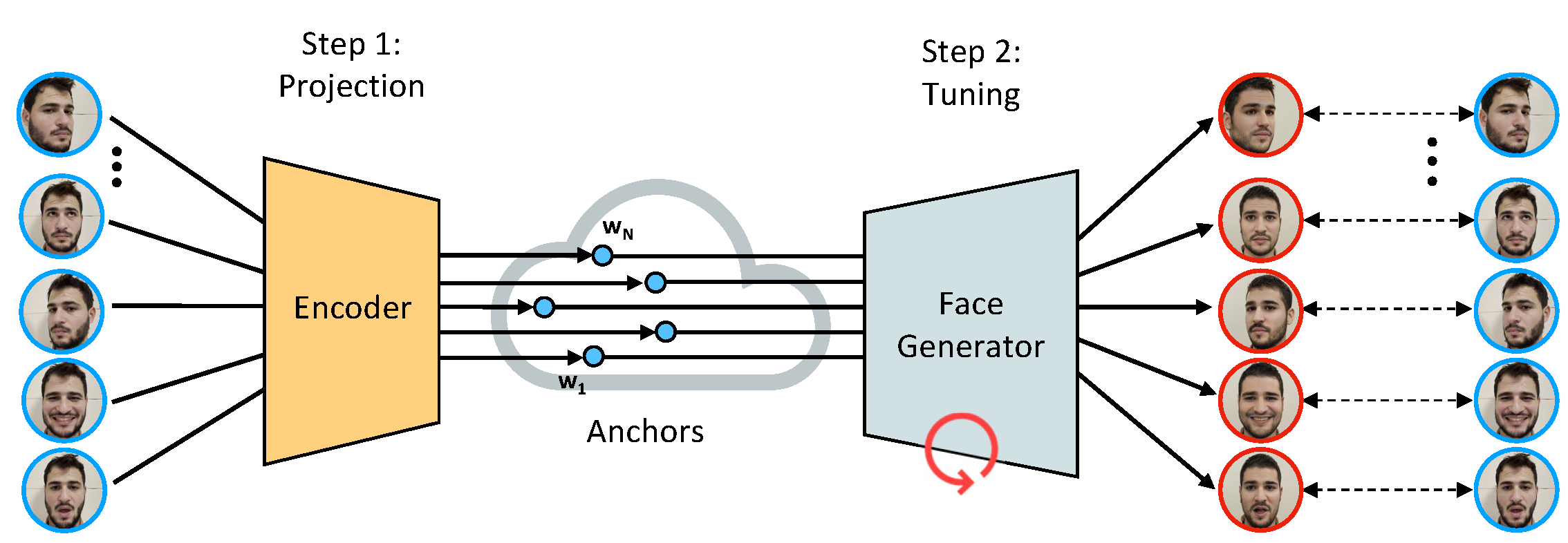
We first apply MyStyle’s tuning method. A set of 𝑁 portrait images of the target individual are projected into StyleGAN’s latent space. The result is a set of anchors that are the nearest possible neighbors. We then tune the generator to reconstruct the input images from their corresponding anchors.
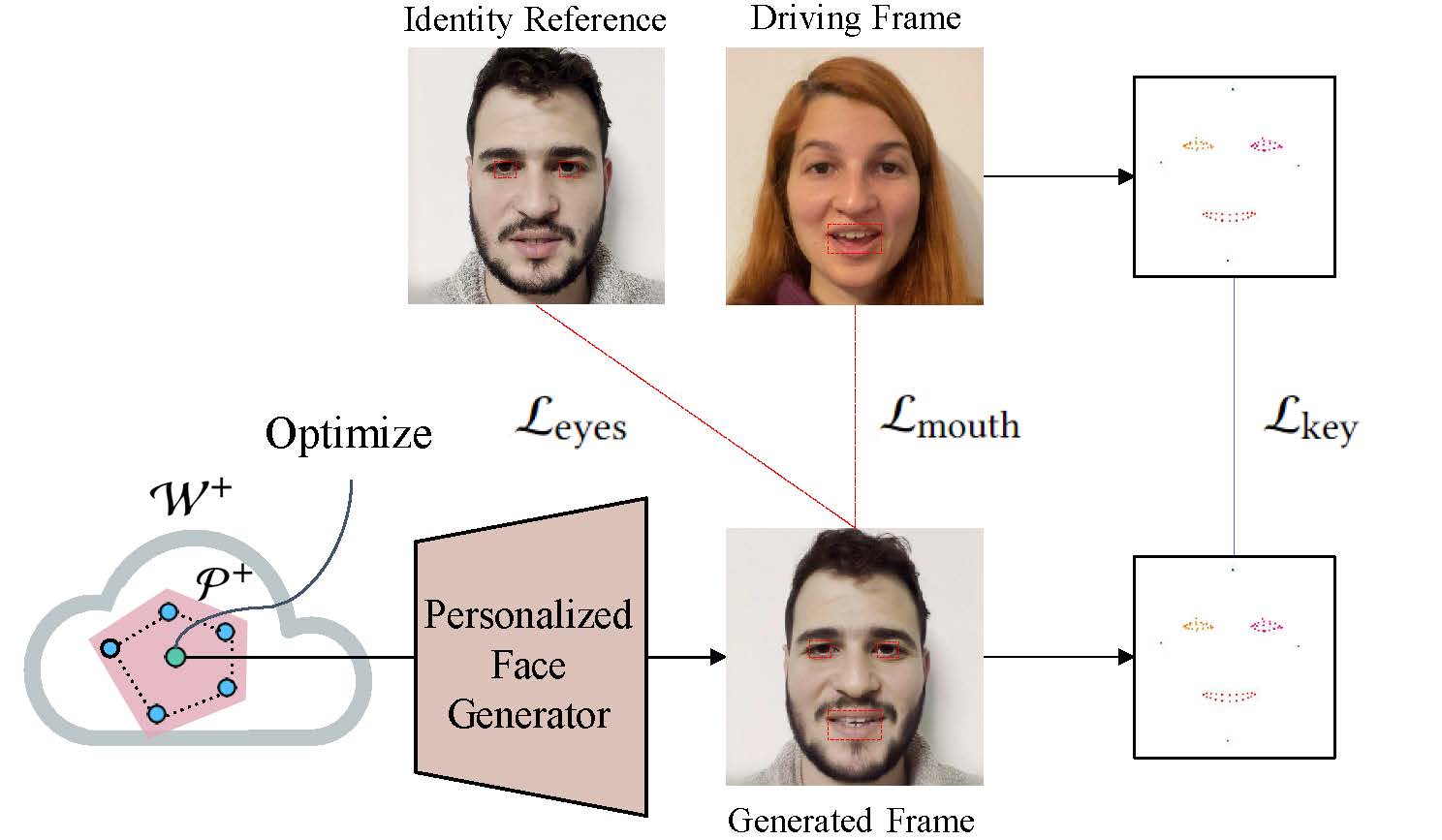
We then apply our latent optimization method for generating a reenacted frame. We operate within the personalized latent space P+ of the generator, ensuring identity preservation and reducing the task to reproducing pose and expression. To this end, we employ two losses to compare the generated and driving frames. First, we penalize differences in a subset of keypoints, which are separately normalized (indicated by color) for each facial part to have zero mean. The subset of normalized keypoints still conveys pose and expression but is more robust to geometry. Second, we apply an 𝐿2 reconstruction loss on pixels in the mouth cavity. In addition, we apply 𝐿2 reconstruction loss on pixels in the irises area between the generated image and the image that generated from the center of P+ in order to preserve the original eye color.
We show examples of Semantic Editing and Stylization.
For semantic editing, instead of generating frames from the optimized latent codes, we first shift them
a constant sized step in the direction of a specific semantic vector.
Passing these shifted latent codes through the generator results in a
reenacted video that was semantically additionally edited.
For stylization, we fine-tune the generator with two prompts – “the Joker” and “a sketch”. The
latent optimization still takes place in the personalized generator,
but the resulting latent codes are passed through the generator
tuned with StyleGAN-NADA to produce the final video frames. The
result is a reenacted video which depicts the target individual but
they are stylized as the Joker or a sketch.
@article{elazary2023pgreenactment,
title={Facial Reenactment Through a Personalized Generator},
author={Elazary, Ariel and Nitzan, Yotam and Cohen-Or, Daniel},
journal={arXiv preprint arXiv:2307.06307},
year={2023}
}